Unit 6 - Notes
Unit 6: Introduction to GPU Architecture
1. Nvidia GPU Architecture: A Case Study
The evolution of Nvidia’s architecture illustrates the shift from fixed-function graphics pipelines to General Purpose GPU (GPGPU) computing. This transition allows GPUs to handle high-performance computing tasks beyond rendering, such as AI training and scientific simulations.
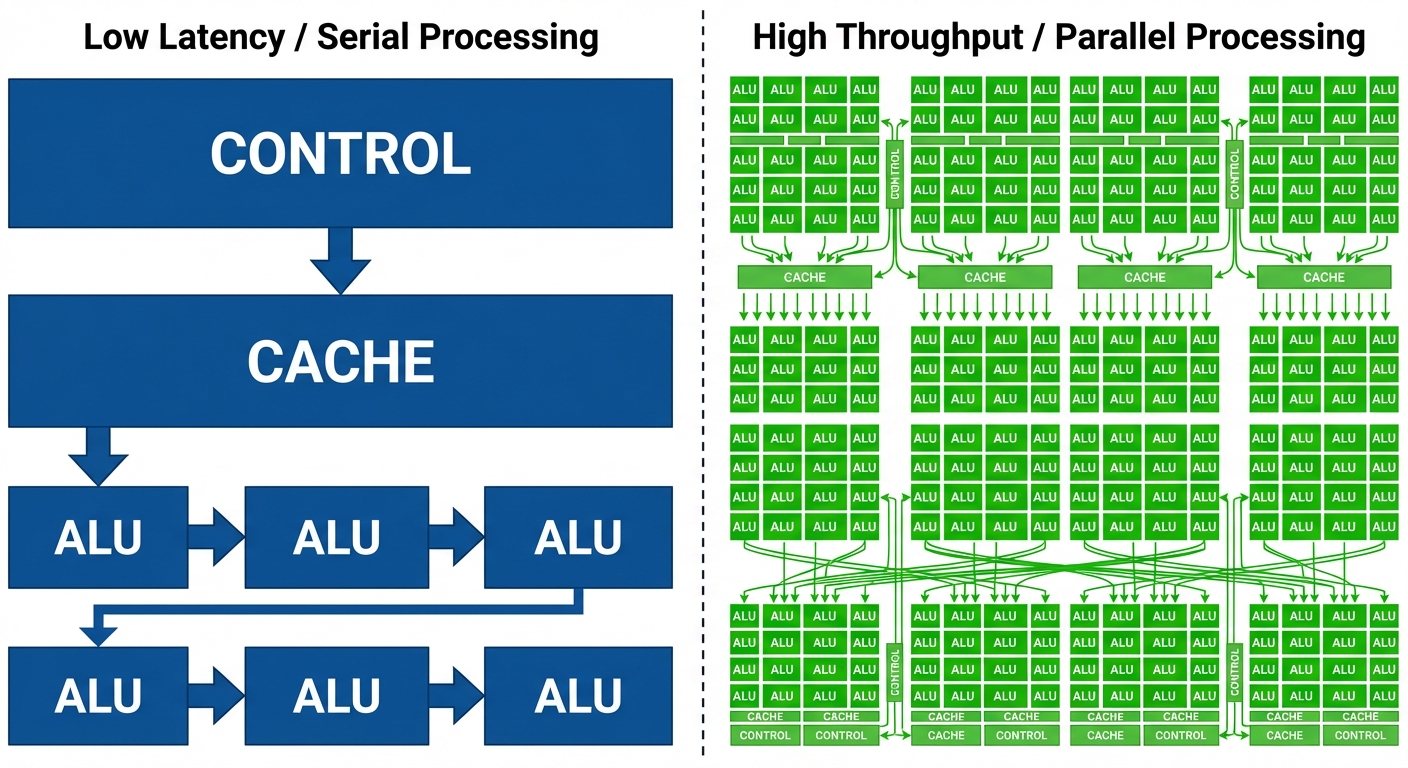
1.1 CPU vs. GPU Design Philosophy
- CPU (Latency Oriented): Designed to minimize the latency of a single thread. It features large caches, complex control logic (branch prediction), and fewer, powerful Arithmetic Logic Units (ALUs).
- GPU (Throughput Oriented): Designed to maximize the total volume of work. It utilizes thousands of smaller, simpler cores to process parallel tasks, hiding memory latency by switching between active threads.
1.2 The CUDA Programming Model
Nvidia utilizes CUDA (Compute Unified Device Architecture). The hierarchy is organized as follows:
- Grid: A collection of blocks that execute a kernel.
- Block: A group of threads that can cooperate via shared memory.
- Thread: The smallest unit of execution.
- Warp: A set of 32 threads executed simultaneously by the hardware.
1.3 Key Architectural Components (Ampere/Hopper Generation)
- Streaming Multiprocessor (SM): The fundamental building block containing CUDA cores, Tensor Cores, and Ray Tracing cores.
- SIMT (Single Instruction, Multiple Threads): Similar to SIMD, but allows individual threads to have their own instruction pointer (though divergence impacts performance).
- Tensor Cores: Specialized execution units designed for matrix multiplication (essential for Deep Learning).
- HBM (High Bandwidth Memory): Stacked memory on the GPU die providing massive bandwidth compared to standard GDDR.
2. Introduction to Supercomputers
Supercomputers represent the pinnacle of high-performance computing (HPC), designed to solve complex mathematical problems requiring massive floating-point calculations.
2.1 Performance Metrics
- FLOPS: Floating Point Operations Per Second.
- Scale:
- PetaFLOPS: operations/sec.
- ExaFLOPS: operations/sec (Current standard for top-tier systems).
2.2 Architectural Approaches
- Cluster Computing: Thousands of individual nodes (servers) connected via high-speed interconnects.
- Heterogeneous Computing: Modern supercomputers (e.g., Frontier, Fugaku) rely heavily on GPU accelerators working alongside CPUs.
- Interconnects: Technologies like InfiniBand or Slingshot are critical to reduce latency between nodes.
2.3 Applications
- Climate modeling and weather prediction.
- Nuclear fusion simulations.
- Genomics and protein folding.
3. Introduction to Qubits and Quantum Computing
Quantum computing diverges fundamentally from classical binary computing by utilizing the principles of quantum mechanics.
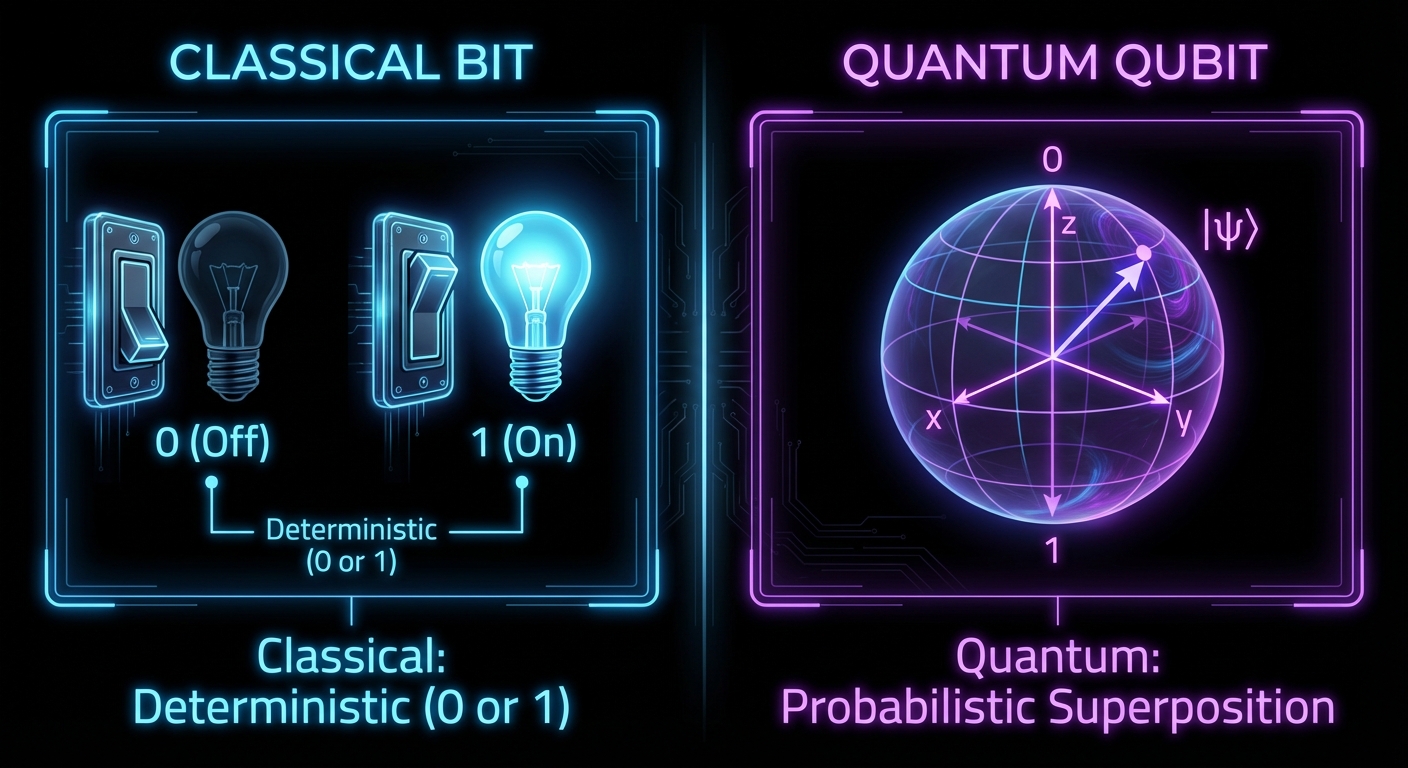
3.1 The Qubit (Quantum Bit)
Unlike a classical bit which is either 0 or 1, a Qubit can exist in a state of superposition.
- Representation: Usually visualized using the Bloch Sphere.
- Mathematical notation:
3.2 Key Principles
- Superposition: The ability to be in multiple states simultaneously until measured.
- Entanglement: A phenomenon where two qubits become linked; the state of one instantly influences the state of the other, regardless of distance.
- Interference: Used to amplify correct answers and cancel out wrong answers in quantum algorithms.
3.3 Challenges
- Decoherence: Interaction with the environment causes qubits to lose their quantum state.
- Error Correction: Quantum states are fragile; thousands of physical qubits may be needed to create one "logical" error-corrected qubit.
4. Latest Technology and Trends in Computer Architecture
As Moore's Law slows (the doubling of transistors per chip becomes harder/expensive), architects are pivoting to new strategies.
4.1 Domain-Specific Architectures (DSAs)
General-purpose CPUs are being supplemented by hardware tailored for specific tasks:
- TPUs/NPUs: Tensor Processing Units and Neural Processing Units for AI.
- DPUs: Data Processing Units for networking and security offloading in data centers.
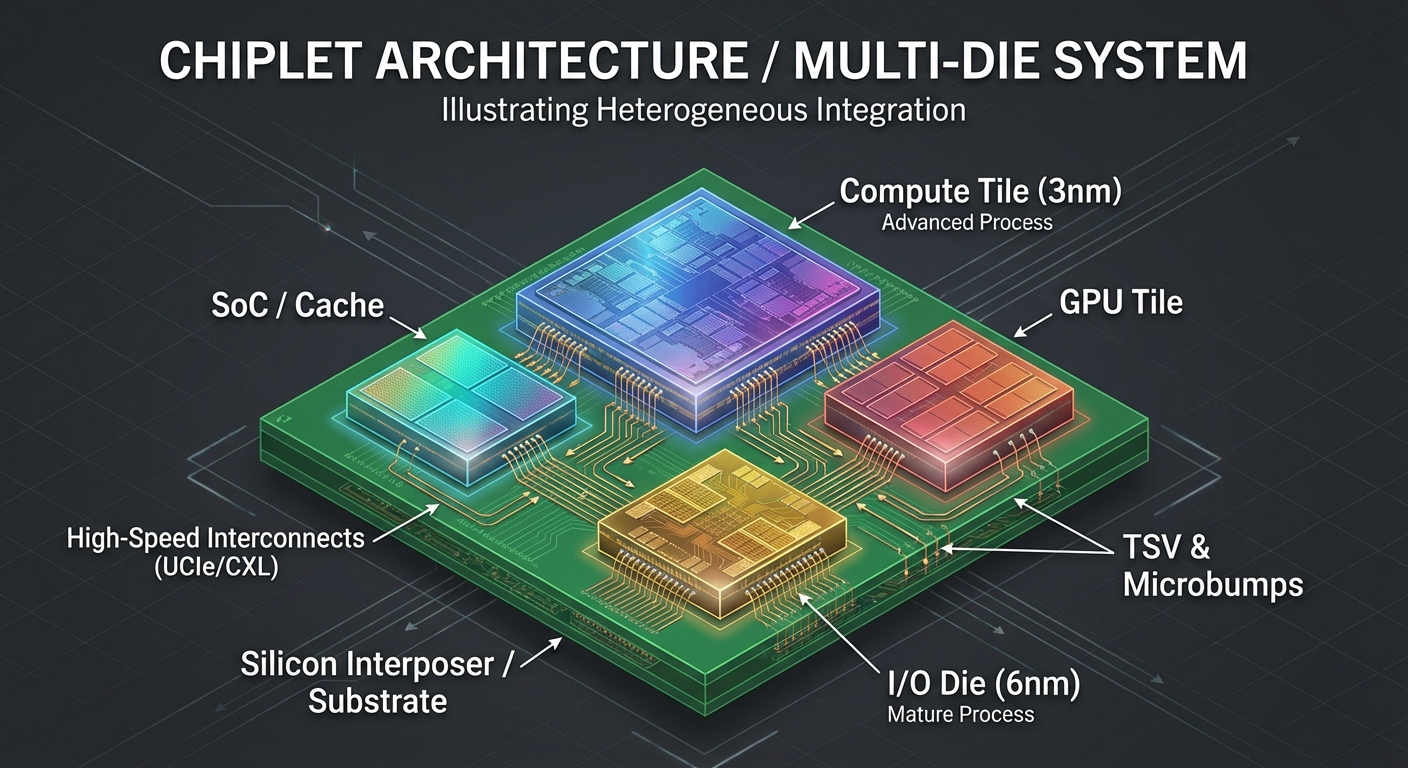
4.2 Chiplets and 3D Stacking
Instead of manufacturing one massive "monolithic" die, manufacturers break the processor into smaller pieces (chiplets) and package them together.
- Benefits: Higher yield rates, ability to mix manufacturing processes (e.g., 5nm for cores, 7nm for I/O).
- Interconnects: UCIe (Universal Chiplet Interconnect Express) is becoming the standard.
4.3 Near-Memory Computing
Moving processing logic closer to (or inside) the memory chips to reduce the energy and latency cost of moving data (the "Von Neumann Bottleneck").
5. Next Generation Processors: Architecture and Microarchitecture
5.1 Architecture (ISA) vs. Microarchitecture
- ISA (Instruction Set Architecture): The interface between software and hardware (e.g., x86-64, ARMv9, RISC-V). What the programmer sees.
- Microarchitecture: The specific hardware implementation of the ISA (e.g., Intel "Golden Cove", AMD "Zen 5"). How the hardware works.
5.2 Emerging Microarchitectural Trends
- Instruction Level Parallelism (ILP): Deeper pipelines and wider superscalar execution (issuing more instructions per clock).
- Branch Prediction: Using AI/Perceptrons inside the CPU to guess which code path will be taken, minimizing pipeline stalls.
- RISC-V: An open-source ISA gaining massive traction for custom silicon, allowing companies to design processors without paying licensing fees to ARM or Intel.
6. Latest Processors for Smartphone, Tablet, and Desktop
6.1 Desktop/Server High-Performance Processors
- Intel (Arrow Lake / Lunar Lake):
- Uses Foveros 3D packaging.
- Transition to tile-based design.
- Introduction of NPU (Neural Processing Unit) directly on the desktop CPU for local AI.
- AMD (Ryzen 9000 series - Zen 5):
- Focus on AVX-512 instruction support for AI.
- High efficiency per watt.
- Continued reliance on the "Infinity Fabric" interconnect.
6.2 Smartphone and Tablet Processors (Mobile SoCs)
Mobile processors are Systems on Chip (SoC), integrating CPU, GPU, Modem, and ISP (Image Signal Processor) on one die.
- Apple Silicon (M4 / A18 Pro):
- Unified Memory Architecture (UMA): CPU and GPU share the same memory pool, eliminating data copying.
- Leading single-threaded performance.
- Qualcomm Snapdragon 8 Gen 3/4:
- Oryon Cores: A shift to custom core designs rather than stock ARM Cortex designs.
- On-device Generative AI capabilities (running LLMs locally).
- MediaTek Dimensity 9300+:
- "All Big Core" design: Removes low-power efficiency cores entirely to maximize performance, relying on the process node (4nm/3nm) for efficiency.
6.3 Hybrid Architectures (big.LITTLE)
Almost all modern consumer processors now use a hybrid approach:
- P-Cores (Performance): High frequency, out-of-order execution, power-hungry. Used for gaming, rendering.
- E-Cores (Efficiency): Lower frequency, simpler pipeline. Used for background tasks, checking email, idling.